리스트
1. 리스트 (List)
리스트는 여러 요소들을 갖는 집합(컬렉션)으로 새로운 요소를 추가하거나 갱신, 삭제하는 일이 가능하다. 파이썬의 리스트는 동적배열(Dynamic Array)로서 자유롭게 확장할 수 있는 구조를 갖는다. 리스트는 그 안의 요소(element)들은 그 값을 자유롭게 변경할 수 있는 Mutable 데이타 타입이다.
리스트의 요소들은 Square bracket([ ])으로 둘러쌓여 컬렉션을 표현하는데, 각 요소들은 서로 다른 타입이 될 수 있으며, 컴마(,)로 구분한다. 요소가 없는 빈 리스트는 "[]"와 같이 표현한다.
a = [] # 빈 리스트
a = ["AB", 10, False]
2. 리스트 인덱싱(Indexing)
리스트의 특정 한 요소만을 선택하기 위하여 인덱싱(Indexing)을 사용하는데, 첫번째요소는 "리스트[0]", 두번째 요소는 "리스트[1]" 처럼 표현한다. 즉, 아래 예제에서 처럼 리스트 a 가 있을 때, a[1] 는 두번째 요소 10을 가리킨다. 파이썬 인덱싱에서 한가지 특별한 표현은 인덱스에 -1, -2 같은 음수를 사용할 수 있다는 점이다. 이 때, -1은 현재 리스트의 마지막 요소를, -2는 뒤에서 두번째 요소를 가리킨다.
a = ["AB", 10, False]
x = a[1] # a의 두번째 요소 읽기
a[1] = "Test" # a의 두번째 요소 변경
y = a[-1] # False
3. 리스트 슬라이싱(Slicing)
리스트에서 일부 부분 요소들을 선택하기 위하여 슬라이스(Slice)를 사용한다. 슬라이스는 "리스트[처음인덱스:마지막인덱스]"와 같이 인덱스 표현에서 부분집합의 범위를 지정하는 것이다. 인덱스는 0 부터 시작하며, 마지막 인덱스를 원하는 "마지막 요소의 인덱스 + 1"을 의미한다. 만약 처음인덱스가 생략되면, 0 부터 시작되며, 마지막 인덱스가 생략되면, 리스트의 끝까지 포함됨을 의미한다.
a = [1, 3, 5, 7, 10]
x = a[1:3] # [3, 5]
x = a[:2] # [1, 3]
x = a[3:] # [7, 10]
4. 리스트 요소 추가,수정,삭제
리스트에 새로운 요소를 추가하기 위해서는 "리스트.append()"를 사용한다. 리스트 요소를 갱신하기 위해서는 리스트 인덱싱을 사용하여 특정요소에 새 값을 넣는다. 리스트 요소를 삭제하기 위해서는 "del 요소"와 같이 특정 요소를 지운다.
a = ["AB", 10, False]
a.append(21.5) # 추가
a[1] = 11 # 변경
del a[2] # 삭제
print(a) # ['AB', 11, 21.5]
5. 리스트 병합과 반복
두 개의 리스트를 병합하기 위해서는 플러스(+)를 사용한다. 이 때 두 리스트는 순서대로 병합된 새로운 하나의 리스트가 된다. 하나의 리스트를 N 번 반복하기 위해서는 "리스트 * N"와 같이 표현할 수 있다. 이는 동일한 리스트를 계속 반복한 새 리스트를 만들게 된다.
# 병합
a = [1, 2]
b = [3, 4, 5]
c = a + b
print(c) # [1, 2, 3, 4, 5]
# 반복
d = a * 3
print(d) # [1, 2, 1, 2, 1, 2]
6. 리스트 검색
리스트 안에 특정 요소를 검색하기 위해서 index() 메서드를 사용한다. 또한 특정 요소가 몇 개 있는지 체크하기 위해서 count() 메서드를 사용할 수 있다.
mylist = "This is a book That is a pencil".split()
i = mylist.index('book') # i = 3
n = mylist.count('is') # n = 2
print(i, n)
7. List Comprehension
리스트의 [...] 괄호 안에 for 루프를 사용하여 반복적으로 표현식(expression)을 실행해서 리스트 요소들을 정의하는 특별한 용법이 있는데, 이를 List Comprehension 이라 부른다. 이는 아래와 같은 문법으로 컬렉션으로부터 요소를 하나씩 가져와 표현식을 실행하여 그 결과를 리스트에 담는 방식이다. 여기서 if 조건식은 옵션으로 추가될 수 있는데 for 루프에서 이 조건식에 맞는 요소만 표현식을 실행하게 된다.
[표현식 for 요소 in 컬렉션 [if 조건식]]
아래 예제는 0부터 9까지 숫자들중 3으로 나눈 나머지가 0인 숫자에 대해 그 제곱에 대한 리스트를 구한 예이다.
list = [n ** 2 for n in range(10) if n % 3 == 0]
print(list)
# 출력: [0, 9, 36, 81]
튜플
1. 튜플 (Tuple)
Tuple은 리스트와 비슷하게 여러 요소들을 갖는 컬렉션이다. 리스트와 다른 점은 Tuple은 새로운 요소를 추가하거나 갱신, 삭제하는 일을 할 수 없다. 즉, Tuple은 한변 결정된 요소를 변경할 수 없는 Immutable 데이타 타입이다. 따라서, Tuple은 컬렉션이 항상 고정된 요소값을 갖기를 원하거나 변경되지 말아야 하는 경우에 사용하게 된다.
튜플의 요소들은 둥근 괄호(...) 를 사용하여 컬렉션을 표현하는데, 각 요소들은 서로 다른 타입이 될 수 있으며, 컴마(,)로 구분한다. 요소가 없는 빈 튜플은 "()"와 같이 표현한다.
t = ("AB", 10, False)
print(t)
특히 요소가 하나일 경우에는 요소 뒤에 콤마를 붙여 명시적으로 Tuple임을 표시해야 한다. 아래 예제를 보면 첫번째 (123) 의 경우, 이는 산술식의 괄호로 인식하여 t1의 타입이 정수가 된다. 이러한 혼동을 방지하기 위해 t2 에서 처럼 (123,) 콤마를 붙여 명시적으로 Tuple임을 표시한다.
t1 = (123)
print(t1) # int 타입
t2 = (123,)
print(t2) # tuple 타입
2. Tuple 인덱싱과 슬라이싱
Tuple은 리스트와 마찬가지로 한 요소를 리턴하는 인덱싱과 특정 부분집합을 리턴하는 슬라이싱을 지원한다. 단, 요소값을 변경하거나 추가 혹은 삭제하는 일은 할 수 없다.
t = (1, 5, 10)
# 인덱스
second = t[1] # 5
last = t[-1] # 10
# 슬라이스
s = t[1:2] # (5)
s = t[1:] # (5, 10)
3. Tuple 병합과 반복
Tuple은 리스트와 마찬가지로 두 개의 튜플을 병합하기 위해 플러스(+)를 사용하고, 하나의 튜플을 N 번 반복하기 위해서는 "튜플 * N"와 같이 표현한다.
# 병합
a = (1, 2)
b = (3, 4, 5)
c = a + b
print(c) # (1, 2, 3, 4, 5)
# 반복
d = a * 3 # 혹은 "d = 3 * a" 도 동일
print(d) # (1, 2, 1, 2, 1, 2)
4. Tuple 변수 할당
Tuple 데이타를 변수에 할당할 때, 각 요소를 각각 다른 변수에 할당할 수도 있다. 예를 들어, 아래 예제에서 첫번째 예의 name 변수는 튜플 전체를 할당받는 변수이지만, 두번째의 firstname, lastname 변수는 튜플에 있는 각 요소를 하나씩 할당받는 변수들이다.
name = ("John", "Kim")
print(name)
# 출력: ('John', 'Kim')
firstname, lastname = ("John", "Kim")
print(lastname, ",", firstname)
# 출력: Kim, John
딕셔너리
1. Dictionary (dict)
Dictionary는 "키(Key) - 값(Value)" 쌍을 요소로 갖는 컬렉션이다. Dictionary는 흔히 Map 이라고도 불리우는데, 키(Key)로 신속하게 값(Value)을 찾아내는 해시테이블(Hash Table) 구조를 갖는다.
파이썬에서 Dictionary는 "dict" 클래스로 구현되어 있다. Dictionary의 키(key)는 그 값을 변경할 수 없는 Immutable 타입이어야 하며, Dictionary 값(value)은 Immutable과 Mutable 모두 가능하다. 예를 들어, Dictionary의 키(key)로 문자열이나 Tuple은 사용될 수 있는 반면, 리스트는 키로 사용될 수 없다.
Dictionary의 요소들은 Curly Brace "{...}" 를 사용하여 컬렉션을 표현하는데, 각 요소들은 "Key:Value"" 쌍으로 되어 있으며, 요소간은 콤마로 구분한다. 요소가 없는 빈 Dictionary는 "{}"와 같이 표현한다. 특정 요소를 찾아 읽고 쓰기 위해서는 "Dictionary변수[키]"와 같이 키를 인덱스처럼 사용한다.
scores = {"철수": 90, "민수": 85, "영희": 80}
v = scores["민수"] # 특정 요소 읽기
scores["민수"] = 88 # 쓰기
print(t)
파이썬의 Dictionary는 생성하기 위해 위의 예제와 같이 {...} 리터럴(Literal)을 사용할 수도 있지만, 또한 dict 클래스의 dict() 생성자를 사용할 수도 있다. dict() 생성자는 (아래 첫번째 예처럼) Key-Value 쌍을 갖는 Tuple 리스트를 받아들이거나 (두번째 예처럼) dict(key=value, key=value, ...) 식의 키-값을 직접 파라미터로 지정하는 방식을 사용할 수 있다.
# 1. Tuple List로부터 dict 생성
persons = [('김기수', 30), ('홍대길', 35), ('강찬수', 25)]
mydict = dict(persons)
age = mydict["홍대길"]
print(age) # 35
# 2. Key=Value 파라미터로부터 dict 생성
scores = dict(a=80, b=90, c=85)
print(scores['b']) #90
2. 추가,수정,삭제,읽기
Dictionary 요소를 수정하기 위해서는 "Dictionary[키]=새값"와 같이 해당 키 인덱스를 사용하여 새 값을 할당하면 된다. Dictionary에 새로운 요소를 추가하기 위해서는 수정 때와 마찬가지로 ("맴[새키]=새값") 새 키에 새 값을 할당한다. Dictionary 요소를 삭제하기 위해서는 "del 요소"와 같이 하여 특정 요소를 지운다.
scores = {"철수": 90, "민수": 85, "영희": 80}
scores["민수"] = 88 # 수정
scores["길동"] = 95 # 추가
del scores["영희"]
print(scores)
# 출력 {'철수': 90, '길동': 95, '민수': 88}
Dictionary에 있는 값들을 모두 출력하기 위해서는 다음과 같이 루프를 사용할 수 있다. 아래 예제에서 for 루프는 scores 맵으로부터 키를 하나씩 리턴하게 된다. 이때 키는 랜덤하게 리턴되는데, 이는 해시테이블의 속성이다. 각 키에 따른 값을 구하기 위해서는 scores[key]와 같이 사용한다.
scores = {"철수": 90, "민수": 85, "영희": 80}
for key in scores:
val = scores[key]
print("%s : %d" % (key, val))
3. 유용한 dict 메서드
Dictonary와 관련하여 dict 클래스에는 여러 유용한 메서드들이 있다. dict 클래스의 keys()는 Dictonary의 키값들로 된 dict_keys 객체를 리턴하고, values()는 Dictonary의 값들로 된 dict_values 객체를 리턴한다.
scores = {"철수": 90, "민수": 85, "영희": 80}
# keys
keys = scores.keys()
for k in keys:
print(k)
# values
values = scores.values()
for v in values:
print(v)
dict의 items()는 Dictonary의 키-값 쌍 Tuple 들로 구성된 dict_items 객체를 리턴한다. 참고로 dict_items 객체를 리스트로 변환하기 위해서는 list()를 사용할 수 있다. 이는 dict_keys, dict_values 객체에도 공히 적용된다.
scores = {"철수": 90, "민수": 85, "영희": 80}
items = scores.items()
print(items)
# 출력: dict_items([('민수', 85), ('영희', 80), ('철수', 90)])
# dict_items를 리스트로 변환할 때
itemsList = list(items)
dict.get() 메서드는 특정 키에 대한 값을 리턴하는데, 이는 Dictionary[키]를 사용하는 것과 비슷하다. 단, Dictionary[키]를 사용하면 키가 없을 때 에러(KeyError)를 리턴하는 반면, get()은 키가 Dictionary에 없을 경우 None을 리턴하므로 더 유용할 수 있다. 물론 get()을 사용하는 대신 해당 키가 Dictionary에 존재하는지 체크하고 Dictionary[키]를 사용하는 방법도 있다. 키가 Dictionary에 존재하는지를 체크하지 위해서는 멤버쉽연산자 in 을 사용하면 된다.
scores = {"철수": 90, "민수": 85, "영희": 80}
v = scores.get("민수") # 85
v = scores.get("길동") # None
v = scores["길동"] # 에러 발생
# 멤버쉽연산자 in 사용
if "길동" in scores:
print(scores["길동"])
scores.clear() # 모두 삭제
print(scores)
dict.update() 메서드는 Dictionary 안의 여러 데이타를 한꺼번에 갱신하는데 유용한 메서드이다. 아래 예제에서 처럼, update() 안에 Dictionary 형태로 여러 데이타의 값을 변경하면, 해당 데이타들이 update() 메서드에 의해 한꺼번에 수정된다.
persons = [('김기수', 30), ('홍대길', 35), ('강찬수', 25)]
mydict = dict(persons)
mydict.update({'홍대길':33,'강찬수':26})
집합
1. Set
Set은 중복이 없는 요소들 (unique elements)로만 구성된 집합 컬렉션이다. Set은 Curly Brace { } 를 사용하여 컬렉션을 표현하는데, 내부적으로 요소들을 순서대로 저장하기 않기 때문에, 순서에 의존하는 기능들을 사용할 수 없다. 만약 set을 정의할 때, 중복된 값을 입력하는 경우, set은 중복된 값을 한번만 가지고 있게 된다. 리스트나 튜플 등을 set으로 변경하기 위해서는 set() 생성자를 사용한다. 이는 리스트에 중복된 값들이 있을 때, 중복 없이 Unique한 값만을 얻고자 할 때 유용하다.
# set 정의
myset = { 1, 1, 3, 5, 5 }
print(myset) # 출력: {1, 3, 5}
# 리스트를 set으로 변환
mylist = ["A", "A", "B", "B", "B"]
s = set(mylist)
print(s) # 출력: {'A', 'B'}
2. Set에서의 추가 및 삭제
Set에 하나의 새로운 요소를 추가하기 위해서는 set 클래스의 add() 메서드를 사용하고, 여러 개의 요소들을 한께번에 추가하기 위해서는 update() 메서드를 사용한다. 또한 Set에서 하나의 요소를 삭제하기 위해서는 remove() 혹은 discard() 메서드를 사용하고, 전체를 모두 지우기 위해서는 clear() 메서드를 사용한다.
myset = {1, 3, 5}
# 하나만 추가
myset.add(7)
print(myset)
# 여러 개 추가
myset.update({4,2,10})
print(myset)
# 하나만 삭제
myset.remove(1)
print(myset)
# 모두 삭제
myset.clear()
print(myset)
3. 집합 연산
수학에서 두개의 집합 간의 연산으로 교집합, 합집합, 차집합이 있는데, set 클래스는 이러한 집합 연산 기능을 제공한다. 즉, a와 b가 set 일 때, 교집합은 a & b (혹은 a.intersection(b)), 합집합은 a | b (혹은 a.union(b)), 차집합은 a - b (혹은 a.differene) 와 같이 구할 수 있다.
a = {1, 3, 5}
b = {1, 2, 5}
# 교집합
i = a & b
# i = a.intersection(b)
print(i)
# 합집합
u = a | b
# u = a.union(b)
print(u)
# 차집합
d = a - b
# d = a.difference(b)
print(d)
함수
1. 함수
함수(function)은 일정한 작업을 수행하는 코드블럭으로 보통 반복적으로 계속 사용되는 코드들을 함수로 정의하여 사용하게 된다. 파이썬에서 함수는 def 키워드를 사용하여 정의되며, 다음과 같은 문법을 갖는다. 여기서 입력파라미터나 리턴값은 구현하는 내용에 따라 있을 수도 있고, 없을 수도 있다.
def 함수명(입력파라미터):
문장1
문장2
[return 리턴값]
아래 예제는 두개의 입력파라미터를 받아들여 이를 더한 값을 리턴하는 함수를 정의하고 이를 사용하는 예이다.
def sum(a, b):
s = a + b
return s
total = sum(4, 7)
print(total)
2. 파라미터 전달방식
파이썬 함수에서 입력 파라미터는 Pass by Assignment에 의해 전달된다. 즉, 호출자(Caller)는 입력 파라미터 객체에 대해 레퍼런스를 생성하여 레퍼런스 값을 복사하여 전달한다. 또한 전달되는 입력파라미터는 Mutable일 수도 있고, Immutable일 수도 있으므로 각 경우에 따라 다른 결과가 일어난다.
만약 입력파라미터가 Mutable 객체이고, 함수가 그 함수 내에서 해당 객체의 내용을 변경하면, 이러한 변경 사항은 호출자(caller)에게 반영된다. 하지만, 함수 내에서 새로운 객체의 레퍼런스를 입력파라미터에 할당한다면, 레퍼런스 자체는 복사하여 전달되었으므로, 호출자에서는 새로운 레퍼런스에 대해 알지 못하게 되고, 호출자 객체는 아무런 변화가 없게 된다.
만약 입력파라미터가 Immutable 객체이면, 입력파라미터의 값이 함수 내에서 변경될 수 없으며, 함수 내에서 새로운 객체의 레퍼런스를 입력파라미터에 할당되어도 함수 외부(Caller)의 값은 변하지 않는다.
# 함수내에서 i, mylist 값 변경
def f(i, mylist):
i = i + 1
mylist.append(0)
k = 10 # k는 int (immutable)
m = [1,2,3] # m은 리스트 (mutable)
f(k, m) # 함수 호출
print(k, m) # 호출자 값 체크
# 출력: 10 [1, 2, 3, 0]
위의 예제에서 함수 f()는 하나의 정수(i)와 하나의 리스트(mylist)를 입력받아, 함수 내에서 그 값들을 변경한다. 정수는 Immutable 타입이므로 함수 내에서 변경된 것이 호출자에 반영되지 않으며, 리스트는 Mutable 타입이므로 추가된 요소가 호출자에서도 반영된다.
3. Default Parameter
함수에 전달되는 입력파라미터 중 호출자가 전달하지 않으면 디폴트로 지정된 값을 사용하게 할 수 있는데, 이를 디폴트 파라미터 혹은 Optional 파라미터라 부른다. 아래 예제에서 factor는 디폴트 파라미터로서 별도로 전달되지 않으면, 그 값이 1로 설정된다.
def calc(i, j, factor = 1):
return i * j * factor
result = calc(10, 20)
print(result)
4. Named Parameter
함수를 호출할 때 보통 함수에 정의된 대로 입력파라미터를 순서대로 전달한다. 이러한 순서의 의한 전달 방식 외에 또 다른 호출 방식으로 "파라미터명=파라미터값" 과 같은 형식으로 파라미터를 전달할 수도 있는데, 이를 Named Parameter라 부른다. Named Parameter를 사용하면 어떤 값이 어떤 파라미터로 전달되는지 쉽게 파악할 수 있는 장점이 있다.
def report(name, age, score):
print(name, score)
report(age=10, name="Kim", score=80)
5. 가변길이 파라미터
함수의 입력파라미터의 갯수를 미리 알 수 없거나, 0부터 N개의 파라미터를 받아들이도록 하고 싶다면, 가변길이 파라미터를 사용할 수 있다. 가변길이 파라미터는 파라미터명 앞에 * 를 붙여 가변길이임을 표시한다. 아래 예제에서 *numbers는 가변길이 파라미터이므로, total()을 호출할 때, 임의의 숫자의 파라미터들을 지정할 수 있다.
def total(*numbers):
tot = 0
for n in numbers:
tot += n
return tot
t = total(1,2)
print(t)
t = total(1,5,2,6)
print(t)
6. 리턴값
함수로부터 호출자로 리턴하기 위해서는 return 문을 사용한다. return문은 단독으로 쓰이면 아무 값을 호출자에게 전달하지 않으며, "return 리턴값" 처럼 쓰이면, 값을 호출자에게 전달한다. 함수에서 리턴되는 값은 하나 이상일 수 있는데, 필요한 수만큼 return 키워드 다음에 콤마로 구분하여 적는다. 예를 들어, return a,b,c 는 3개의 값을 리턴한다. 하지만, 기술적으로 좀 더 깊이 설명하면, 이는 (a,b,c) 세개의 값을 포함하는 Tuple 하나를 리턴하는 것으로 함수는 항상 하나의 리턴값을 전달한다고 볼 수 있다.
def calc(*numbers):
count = 0
tot = 0
for n in numbers:
count += 1
tot += n
return count, tot
count, sum = calc(1,5,2,6) # (count, tot) 튜플을 리턴
print(count, sum)
모듈
1. 모듈
모듈(Module)은 파이썬 코드를 논리적으로 묶어서 관리하고 사용할 수 있도록 하는 것으로, 보통 하나의 파이썬 .py 파일이 하나의 모듈이 된다. 모듈 안에는 함수, 클래스, 혹은 변수들이 정의될 수 있으며, 실행 코드를 포함할 수도 있다.
파이썬은 기본적으로 상당히 많은 표준 라이브러리 모듈들을 제공하고 있으며, 3rd Party에서도 많은 파이쎤 모듈들을 제공하고 있다. 이러한 모듈들을 사용하기 위해서는 모듈을 import하여 사용하면 되는데, import 문은 다음과 같이 하나 혹은 복수의 모듈을 불러들일 수 있다.
import 모듈1[, 모듈2[,... 모듈N]
예를 들어, 아래 예제는 표준 라이브러리 중 수학과 관련된 함수들을 모아 놓은 "math" 모듈을 import 하여 그 모듈 안에 있는 factorial() 함수를 사용하는 예이다.
import math
n = math.factorial(5)
하나의 모듈 안에는 여러 함수들이 존재할 수 있는데, 이 중 하나의 함수만을 불러 사용하기 위해서는 아래와 같이 "from 모듈명 import 함수명"이라는 표현을 사용할 수 있다. 이렇게 from...import... 방식으로 import 된 함수는 호출시 "모듈명.함수명"이 아니라 직접 "함수명"만을 사용한다.
# factorial 함수만 import
from math import factorial
n = factorial(5) / factorial(3)
하나의 모듈 안에는 있는 여러 함수를 사용하기 위해 from... import (함수1, 함수2) 와 같이 import 뒤에 사용할 함수를 나열할 수도 있다. 또한, 모든 함수를 불러 사용하기 위해서는 "from 모듈명 import *" 와 같이 asterisk(*)를 사용할 수 있다. 이렇게 from...import... 방식으로 import 된 함수는 호출시 모듈명 없이 직접 함수명을 사용한다.
# 여러 함수를 import
from math import (factorial,acos)
n = factorial(3) + acos(1)
# 모든 함수를 import
from math import *
n = sqrt(5) + fabs(-12.5)
함수의 이름이 길거나 어떤 필요에 의해 함수의 이름에 Alias를 주고 싶은 경우가 있는데, 이 때는 아래와 같이 "함수명 as Alias" 와 같은 표현을 사용할 수 있다.
# factorial() 함수를 f()로 사용 가능
from math import factorial as f
n = f(5) / f(3)
2. 모듈의 위치
파이썬에서 모듈을 import 하면 그 모듈을 찾기 위해 다음과 같은 경로를 순서대로 검색한다.
- 현재 디렉토리
- 환경변수 PYTHONPATH에 지정된 경로
Python이 설치된 경로 및 그 밑의 라이브러리 경로
이러한 경로들은 모두 취합되어 시스템 경로인 sys.path에 리스트 형태로 저장된다. 따라서, 모듈이 검색되는 검색 경로는 sys.path를 체크하면 쉽게 알 수 있다. 모듈을 import 하면 sys.path에 있는 경로 순서대로 모듈을 찾아 import하다가 만약 끝까지 찾지 못하면 에러가 발생된다.
sys.path를 사용하기 위해서는 sys라는 시스템 모듈을 import 해야 하며, sys.path는 임의로 수정할 수도 있다. 예를 들어, 기존 sys.path에 새 경로를 추가(append)하면, 추가된 경로도 이후 모듈 검색 경로에 포함된다아래는 sys.path를 출력해 본 예인데, sys.path[0]의 값은 빈 문자열(empty string)로 이는 현재 디렉토리를 가리킨다. 즉, 먼저 현재 디렉토리부터 찾는다는 뜻이다. 마지막 라인은 sys.path.append()를 사용하여 새 경로를 추가하는 예를 든 것이다.

3. 모듈의 작성
프로그램을 모듈로 나누어 코딩하고 관리하는 것은 종종 많은 잇점이 있다. 사용자 함수 혹은 클래스를 묶어 모듈화하고, 이를 불러 사용하는 방법을 간략히 살펴보자. 우선 아래 두 개의 함수(add와 substract)를 mylib.py 라는 모듈에 저장한다.
# mylib.py
def add(a, b):
return a + b
def substract(a, b):
return a - b
모듈 mylib.py가 있는 디렉토리에서 그 모듈을 import 한 후, mylib의 함수들을 사용한다.
# exec.py
from mylib import *
i = add(10,20)
i = substract(20,5)
파이썬 모듈 .py 파일은 import 하여 사용할 수 있을 뿐만 아니라, 해당 모듈 파일 안에 있는 스크립트 전체를 바로 실행할 수도 있다. 파이썬에서 하나의 모듈을 import 하여 사용할 때와 스크립트 전체를 실행할 때를 동시에 지원하기 위하여 흔히 관행적으로 모듈 안에서 __name__ 을 체크하곤 한다. 파이썬에서 모듈을 import해서 사용할 경우 그 모듈 안의 __name__ 은 해당 모듈의 이름이 되며, 모듈을 스크립트로 실행할 경우 그 모듈 안의 __name__ 은 "__main__" 이 된다. 예를 들어, run.py이라는 모듈을 import 하여 사용할 경우 __name__ 은 run.py가 되며, "python3.5 run.py"와 같이 인터프리터로 스크립트를 바로 실행할 때 __name__ 은 __main__ 이 된다.
# run.py
import sys
def openurl(url):
#..본문생략..
print(url)
if __name__ == '__main__':
openurl(sys.argv[1])
위와 같은 run.py 모듈을 아래와 같이 스크립트로 실행할 때 "if __name__ ..." 조건문은 참이 되어 openurl(sys.argv[1]) 가 실행된다. 여기서 참고로 sys.argv는 Command Line 아규먼트들을 갖는 리스트로서 아래 예제에서 argv[0]은 run.py, argv[1]은 google.com이 된다.
$ python3.5 run.py google.com
google.com
하지만 아래와 같이 모듈을 import하여 사용할 때는 "if __name__ ..." 문이 거짓이 되어 openurl() 함수가 바로 실행되지 않고, 그 함수 정의만 import 된다. 따라서 이 경우 사용자는 명시적으로 openurl() 함수를 호출하여 사용해야 한다.
$ python3.5
>>> from run import *
>>> openurl('google.com')
패키지
1. 패키지
파이썬에서 모듈은 하나의 .py 파일을 가리키며, 패키지는 이러한 모듈들을 모은 컬렉션을 가리킨다. 파이썬의 패키지는 하나의 디렉토리에 놓여진 모듈들의 집합을 가리키는데, 그 디렉토리에는 일반적으로 __init__.py 라는 패키지 초기화 파일이 존재한다 (주: Python 3.3 이후부터는 init 파일이 없어도 패키지로 인식이 가능하다).
패키지는 모듈들의 컨테이너로서 패키지 안에는 또다른 서브 패키지를 포함할 수도 있다. 파일시스템으로 비유하면 패키지는 일반적으로 디렉토리에 해당하고, 모듈은 디렉토리 안의 파일에 해당한다.
파이썬으로 큰 프로젝트를 수행하게 될 때, 모든 모듈을 한 디렉토리에 모아 두기 보다는 계층적인 카테고리로 묶어서 패키지별로 관리하는 것이 편리하고 효율적이다. 파이썬 프로젝트의 루트로부터 각 영역별로 디렉토리/서브디렉토리를 만들고 그 안에 논리적으로 동일한 기능을 하는묶을 모듈들을 같이 두어 패키지를 만들 수 있다. 이때 패키지는 "디렉토리.서브디렉토리"와 같이 엑세스하고 패키지내 모듈은 "디렉토리.서브디렉토리.모듈" 과 같이 엑세스할 수 있다. 즉, 각 디렉토리 및 모듈 사이에 점(.)을 사용한다.
간단한 예로 다음 그림과 같이 models/account 폴더를 만들고, 그 안에 bill.py 라는 모듈이 있다고 가정하자. models/account 폴더에는 그 폴더가 일반 폴더가 아닌 패키지임을 표시하기 위해 빈 __init__.py 파일을 만들었다 (버젼 3.3+ 에선 Optional).
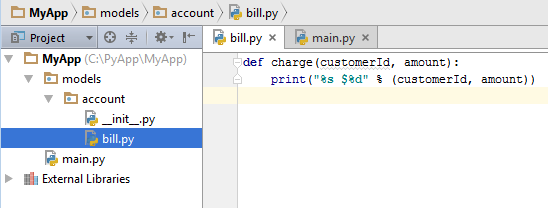
패키지 안에 있는 모듈을 import 하여 사용하기 위해서는 일반 모듈처럼 import문 혹은 from...import... 문을 사용한다. 먼저 import문을 보면 import문은 모듈을 import 하는 것이므로, 패키지내 모듈을 import하기 위해서는 "import 패키지명.모듈명"과 같이 패키지명을 앞에 붙여 사용한다. 아래 예제에서 보면, bill.py 모듈을 import 하기 위해 "import models.account.bill" 와 같이 전체 패키지명을 함께 표시하였음을 볼 수 있다. 또한 모듈내 함수를 사용하기 위하여 models.account.bill.charge()와 같이 패키지명과 모듈명도 함께 써 주어야 한다.
# 모듈 import
# import 패키지.모듈
import models.account.bill
models.account.bill.charge(1, 50)
다음으로 from ... import ... 문을 살펴보자. 먼저 패키지 모듈을 import 하기 위해 "from 패키지명 import 모듈명" 문을 사용할 수 있다. 아래 예제를 보면, from 뒤에 패키지명 models.account을 사용하였고, import 다음 모듈명 bill을 사용하였다. 이 방식은 해당 모듈 내의 모든 함수를 사용할 수 있는데, bill.charge()와 같이 모듈명.함수명()으로 함수를 호출한다.
만약 패키지 모듈 내의 특정 함수만 import하여 사용하고 싶다면, "from 패키지명.모듈명 import 함수명" 과 같이 from 에 "패키지명.모듈명"을 적고 import 뒤에 함수명을 적는다.
# 모듈안의 모든 함수 import
# from 패키지명 import 모듈명
from models.account import bill
bill.charge(1, 50)
# 특정 함수만 import
# from 패키지명.모듈명 import 함수명
from models.account.bill import charge
charge(1, 50)
2. __init__.py
패키지에는 __init__.py 라는 특별한 파일이 있는데, 이 파일은 기본적으로 그 폴더가 일반 폴더가 아닌 패키지임을 표시하기 위해 사용될 뿐만 아니라, 패키지를 초기화하는 파이썬 코드를 넣을 수 있다. 버젼 3.3 이상에서는 이 파일이 없어도 패키지로 사용할 수 있지만, 호환성을 위해 두는 것이 좋다. __init__.py 파일에서 중요한 변수로 __all__ 이라는 리스트 변수가 있는데, 이 변수는 "from 패키지명 import *" 문을 사용할 때, 그 패키지 내에서 import 가능한 모듈들의 리스트를 담고 있다. 즉, __all__ 에 없는 모듈은 import 되지 않고 에러가 발생한다.
아래 예제는 __init__.py 파일 안에 bill 모듈을 허락한 후, from ... import * 를 사용하여 해당 패지키로부터 허락된 모든 모듈을 import 한 후 bill.charge() 함수를 사용하는 예이다.
# __init__.py 파일의 내용
__all__ = ['bill']
# 패지키내 모든 모듈 import
# from 패키지명 import *
from models.account import *
bill.charge(1, 50)
클래스
1. 클래스
파이썬은 객체지향 프로그래밍(OOP, Object Oriented Programming)을 기본적으로 지원하고 있다. 파이썬에서 객체지향 프로그래밍의 기본 단위인 클래스를 만들기 위해서는 아래와 같이 "class 클래스명" 을 사용하여 정의한다. 클래스명은 PEP 8 Coding Convention에 가이드된 대로 각 단어의 첫 문자를 대문자로 하는 CapWords 방식으로 명명한다. 아래 예제는 MyClass라는 클래스를 정의한 것으로 별도의 클래스 멤버를 정의하지 않은 가장 간단한 빈 클래스이다. 클래스 정의 내의 pass문은 빈 동작 혹은 아직 구현되지 않았음을 의미하는 것으로 여기서는 빈 클래스를 의미한다.
class MyClass:
pass
2. 클래스 멤버
클래스는 메서드(method), 속성(property), 클래스 변수(class variable), 인스턴스 변수(instance variable), 초기자(initializer), 소멸자(destructor) 등의 여러 맴버들을 가질 수 있는데, 크게 나누면 데이타를 표현하는 필드와 행위를 표현하는 메서드로 구분할 수 있다. 파이썬에서 이러한 필드와 메서드는 모두 그 객체의 attribute 라고 한다. 다른 OOP 언어와 달리 파이썬은 Dynamic Language로서 새로운 attribute를 동적으로 추가할 수 있고, 메서드도 일종의 메서드 객체로 취급하여 attribute에 포함한다.
메서드
메서드는 클래스의 행위를 표현하는 것으로 클래스 내의 함수로 볼 수 있다. 파이썬에서 메서드는 크게 인스턴스 메서드(instance method), 정적 메서드(static method), 클래스 메서드(class method)가 있다. 가장 흔히 쓰이는 인스턴스 메서드는 인스턴스 변수에 엑세스할 수 있도록 메서드의 첫번째 파라미터에 항상 객체 자신을 의미하는 "self"라는 파라미터를 갖는다. 아래 예제에서 calcArea()가 인스턴스 메서드에 해당된다. 인스턴스 메서드는 여러 파라미터를 가질 수 있지만, 첫번째 파라미터는 항상 self 를 갖는다.
class Rectangle:
count = 0 # 클래스 변수
# 초기자(initializer)
def __init__(self, width, height):
# self.* : 인스턴스변수
self.width = width
self.height = height
Rectangle.count += 1
# 메서드
def calcArea(self):
area = self.width * self.height
return area
클래스 변수
클래스 정의에서 메서드 밖에 존재하는 변수를 클래스 변수(class variable)라 하는데, 이는 해당 클래스를 사용하는 모두에게 공용으로 사용되는 변수이다. 클래스 변수는 클래스 내외부에서 "클래스명.변수명" 으로 엑세스 할 수 있다. 위의 예제에서 count는 클래스변수로서 "Rectangle.count"와 같이 엑세스할 수 있다.
인스턴스 변수
하나의 클래스로부터 여러 객체 인스턴스를 생성해서 사용할 수 있다. 클래스 변수가 하나의 클래스에 하나만 존재하는 반면, 인스턴스 변수는 각 객체 인스턴스마다 별도로 존재한다. 클래스 정의에서 메서드 안에서 사용되면서 "self.변수명"처럼 사용되는 변수를 인스턴스 변수(instance variable)라 하는데, 이는 각 객체별로 서로 다른 값을 갖는 변수이다. 인스턴스 변수는 클래스 내부에서는 self.width 과 같이 "self." 을 사용하여 엑세스하고, 클래스 밖에서는 "객체변수.인스턴스변수"와 같이 엑세스 한다.
Python은 다른 언어에서 흔히 사용하는 public, protected, private 등의 접근 제한자 (Access Modifier)를 갖지 않는다. Python 클래스는 기본적으로 모든 멤버가 public이라고 할 수 있다. Python 코딩 관례(Convention)상 내부적으로만 사용하는 변수 혹은 메서드는 그 이름 앞에 하나의 밑줄(_) 을 붙인다. 하지만 이는 코딩 관례에 따른 것일 뿐 실제 밑줄 하나를 사용한 멤버도 public 이므로 필요하면 외부에서 엑세스할 수 있다.
만약 특정 변수명이나 메서드를 private으로 만들어야 한다면 두개의 밑줄(__)을 이름 앞에 붙이면 된다.
def __init__(self, width, height):
self.width = width
self.height = height
# private 변수 __area
self.__area = width * height
# private 메서드
def __internalRun(self):
pass
Initializer (초기자)
클래스로부터 새 객체를 생성할 때마다 실행되는 특별한 메서드로 __init__() 이라는 메서드가 있는데, 이를 흔히 클래스 Initializer 라 부른다 (주: 파이썬에서 두개의 밑줄 (__) 시작하고 두개의 밑줄로 끝나는 레이블은 보통 특별한 의미를 갖는다). Initializer는 클래스로부터 객체를 만들 때, 인스턴스 변수를 초기화하거나 객체의 초기상태를 만들기 위한 문장들을 실행하는 곳이다. 위의 __init__() 예제를 보면, width와 height라는 입력 파라미터들을 각각 self.width와 self.height라는 인스턴스변수에 할당하여 객체 내에서 계속 사용할 수 있도록 준비하고 있다.
(주: Python의 Initializer는 C#/C++/Java 등에서 일컫는 생성자(Constructor)와 약간 다르다. Python에서 클래스 생성자(Constructor)는 실제 런타임 엔진 내부에서 실행되는데, 이 생성자(Constructor) 실행 도중 클래스 안에 Initializer가 있는지 체크하여 만약 있으면 Initializer를 호출하여 객체의 변수 등을 초기화한다.).
정적 메서드와 클래스 메서드
인스턴스 메서드가 객체의 인스턴스 필드를 self를 통해 엑세스할 수 있는 반면, 정적 메서드는 이러한 self 파라미터를 갖지 않고 인스턴스 변수에 엑세스할 수 없다. 따라서, 정적 메서드는 보통 객체 필드와 독립적이지만 로직상 클래스내에 포함되는 메서드에 사용된다. 정적 메서드는 메서드 앞에 @staticmethod 라는 Decorator를 표시하여 해당 메서드가 정적 메서드임을 표시한다.
클래스 메서드는 메서드 앞에 @classmethod 라는 Decorator를 표시하여 해당 메서드가 클래스 메서드임을 표시한다. 클래스 메서드는 정적 메서드와 비슷한데, 객체 인스턴스를 의미하는 self 대신 cls 라는 클래스를 의미하는 파라미터를 전달받는다. 정적 메서드는 이러한 cls 파라미터를 전달받지 않는다. 클래스 메서드는 이렇게 전달받은 cls 파라미터를 통해 클래스 변수 등을 엑세스할 수 있다.
일반적으로 인스턴스 데이타를 엑세스 할 필요가 없는 경우 클래스 메서드나 정적 메서드를 사용하는데, 이때 보통 클래스 변수를 엑세스할 필요가 있을 때는 클래스 메서드를, 이를 엑세스할 필요가 없을 때는 정적 메서드를 사용한다.
아래 예제에서 isSquare() 메서드는 정적 메서드로서 cls 파라미터를 전달받지 않고 메서드 내에서 클래스 변수를 사용하지 않고 있다. 반면, printCount() 메서드는 클래스 메서드로서 cls 파라미터를 전달받고 메서드 내에서 클래스 변수 count 를 사용하고 있다.
class Rectangle:
count = 0 # 클래스 변수
def __init__(self, width, height):
self.width = width
self.height = height
Rectangle.count += 1
# 인스턴스 메서드
def calcArea(self):
area = self.width * self.height
return area
# 정적 메서드
@staticmethod
def isSquare(rectWidth, rectHeight):
return rectWidth == rectHeight
# 클래스 메서드
@classmethod
def printCount(cls):
print(cls.count)
# 테스트
square = Rectangle.isSquare(5, 5)
print(square) # True
rect1 = Rectangle(5, 5)
rect2 = Rectangle(2, 5)
rect1.printCount() # 2
그 밖의 특별한 메서드들
파이썬에는 Initializer 이외에도 객체가 소멸될 때 (Garbage Collection 될 때) 실행되는 소멸자(__del__) 메서드, 두 개의 객체를 ( + 기호로) 더하는 __add__ 메서드, 두 개의 객체를 ( - 기호로) 빼는 __sub__ 메서드, 두 개의 객체를 비교하는 __cmp__ 메서드, 문자열로 객체를 표현할 때 사용하는 __str__ 메서드 등 많은 특별한 용도의 메서드들이 있다. 아래 예제는 이 중 __add__() 메서드에 대한 예이다.
def __add__(self, other):
obj = Rectangle(self.width + other.width, self.height + other.height)
return obj
# 사용 예
r1 = Rectangle(10, 5)
r2 = Rectangle(20, 15)
r3 = r1 + r2 # __add__()가 호출됨
3. 객체의 생성과 사용
클래스를 사용하기 위해서는 먼저 클래스로부터 객체(Object)를 생성해야 한다. 파이썬에서 객체를 생성하기 위해서는 "객체변수명 = 클래스명()"과 같이 클래스명을 함수 호출하는 것처럼 사용하면 된다. 만약 __init__() 함수가 있고, 그곳에 입력 파라미터들이 지정되어 있다면, "클래스명(입력파라미터들)"과 같이 파라미터를 괄호 안에 전달한다. 이렇게 전달된 파라미터들은 Initializer 에서 사용된다.
아래 예제를 보면, Rectangle 클래스로부터 r 이라는 객체를 생성 하고 있는데, Rectangle(2, 3)와 같이 2개의 파라미터를 전달하고 있다. 이는 Rectangle 초기자에서 각각 width와 height 인스턴스 변수를 초기화하는데 사용된다.
# 객체 생성
r = Rectangle(2, 3)
# 메서드 호출
area = r.calcArea()
print("area = ", area)
# 인스턴스 변수 엑세스
r.width = 10
print("width = ", r.width)
# 클래스 변수 엑세스
print(Rectangle.count)
print(r.count)
클래스로부터 생성된 객체(Object)로부터 클래스 멤버들을 호출하거나 엑세스할 수 있다. 인스턴스 메서드는 "객체변수.메서드명()"과 같이 호출할 수 있는데, 위의 예제에선 r.calcArea() 이 메서드 호출에 해당된다. 인스턴스 변수는 "객체변수.인스턴스변수" 으로 표현되며, 값을 읽거나 변경하는 일이 가능하다. 위의 예제 r.width = 10 은 인스턴스변수 width 에 새 값을 할당하는 예이다.
파이썬에서 특히 클래스 변수를 엑세스할 때, "클래스명.클래스변수명" 혹은 "객체명.클래스변수명"을 둘 다 허용하기 때문에 약간의 혼란을 초래할 수 있다. 예를 들어, 위의 예제에서 Rectangle.count 혹은 r.count은 모두 클래스 변수 count를 엑세스하는 경우로서 이 케이스에는 동일한 값을 출력한다.
하지만, 아래 예제와 같이 Rectangle 클래스의 클래스 변수 count를 Rectangle.count로 할당하지 않고 객체 r 로부터 할당하면 혼돈스러운 결과를 초래하게 된다.
파이썬에서 한 객체의 attribute에 값이 할당되면 (예를 들어, r.count = 10), 먼저 해당 객체에 이미 동일한 attribute가 있는지 체크해서 있으면 새 값으로 치환하고, 만약 그 attribute가 없으면 객체에 새로운 attribute를 생성하고 값을 할당한다. 즉, r.count = 10 의 경우 클래스 변수인 count를 사용하는 것이 아니라 새로 그 객체에 추가된 인스턴스 변수를 사용하게 되므로 클래스 변수값은 변경되지 않는다.
파이썬에서 한 객체의 attribute를 읽을 경우에는 먼저 그 객체에서 attribute를 찾아보고, 없으면 그 객체의 소속 클래스에서 찾고, 다시 없으며 상위 Base 클래스에서 찾고, 그래도 없으면 에러를 발생시킨다. 따라서, 위 예제에서 클래스 변수값이 출력된 이유는 값을 할당하지 않고 읽기만 했기 때문에, r 객체에 새 인스턴스 변수를 생성하지 않게 되었고, 따라서 객체의 attribute가 없어서 클래스의 attribute를 찾았기 때문이다.
이러한 혼돈을 피하기 위해 클래스 변수를 엑세스할 때는 클래스명을 사용하는 것이 좋다.
r = Rectangle(2, 3)
Rectangle.count = 50
r.count = 10 # count 인스턴스 변수가 새로 생성됨
print(r.count, Rectangle.count) # 10 50 출력
4. 클래스 상속과 다형성
파이썬은 객체지향 프로그래밍의 상속(Inheritance)을 지원하고 있다. 클래스를 상속 받기 위해서는 파생클래스(자식클래스)에서 클래스명 뒤에 베이스클래스(부모클래스) 이름을 괄호와 함께 넣어 주면 된다. 즉, 아래 예제에서 Dog 클래스는 Animal 클래스로부터 파생된 파생클래스이며, Duck 클래스도 역시 Animal 베이스클래스로부터 파생되고 있다. (주: 파이썬은 복수의 부모클래스로부터 상속 받을 수 있는 Multiple Inheritance를 지원하고 있다.)
class Animal:
def __init__(self, name):
self.name = name
def move(self):
print("move")
def speak(self):
pass
class Dog (Animal):
def speak(self):
print("bark")
class Duck (Animal):
def speak(self):
print("quack")
파생클래스는 베이스클래스의 멤버들을 호출하거나 사용할 수 있으며, 물론 파생클래스 자신의 멤버들을 사용할 수 있다.
dog = Dog("doggy") # 부모클래스의 생성자
n = dog.name # 부모클래스의 인스턴스변수
dog.move() # 부모클래스의 메서드
dog.speak() # 파생클래스의 멤버
파이썬은 객체지향 프로그래밍의 다형성(Polymorphism)을 또한 지원하고 있다. 아래 예제는 animals 라는 리스트에 Dog 객체와 Duck 객체를 넣고 이들의 speak() 메서드를 호출한 예이다. 코드 실행 결과를 보면 객체의 타입에 따라 서로 다른 speak() 메서드가 호출됨을 알 수 있다.
animals = [Dog('doggy'), Duck('duck')]
for a in animals:
a.speak()
예외처리
1. 예외처리
프로그램에서 에러가 발생했을 때, 에러를 핸들링하는 기능으로 try...except 문을 사용할 수 있다. 즉, try 블럭 내의 어느 문장에서 에러가 발생하면, except 문으로 이동하고 예외 처리를 할 수 있다. try 문은 또한 finally 문을 가질 수도 있는데, finally 블럭은 try 블럭이 정상적으로 실행되든, 에러가 발생하여 except 블럭이 실행되든 상관없이 항상 마지막에 실행된다.
try:
문장1
문장2
except:
예외처리
finally:
마지막에 항상 수행
위의 except 문은 except 뒤에 아무것도 쓰지 않았는데, 이는 어떤 에러이든 발생하면 해당 except 블럭을 수행하라는 의미이다. except 뒤에 "에러타입"을 적거나 "에러타입 as 에러변수"를 적을 수가 있는데, 이는 특정한 타입의 에러가 발생했을 때만 해당 except 블럭을 실행하라는 뜻이다. 에러변수까지 지정했으면, 해당 에러변수를 excep 블럭 안에서 사용할 수 있다. 아래 예제를 보면, except가 2개 있는데, 첫번째는 IndexError가 발생했을 때만 그 블럭을 실행하며, 두번째는 일반적인 모든 Exception 이 발생했을 때 해당 블럭을 실행하라는 의미이다. 즉, 먼저 IndexError 인지 검사하고, 아니면 다음 except를 계속 순차적으로 체크하게 된다. except가 여러 개인 경우는 범위가 좁은 특별한 에러타입을 앞에 쓰고 보다 일반적인 에러타입을 뒤에 쓰게 된다.
def calc(values):
sum = None
# try...except...else
try:
sum = values[0] + values[1] + values[2]
except IndexError as err:
print('인덱스에러')
except Exception as err:
print(str(err))
else:
print('에러없음')
finally:
print(sum)
# 테스트
calc([1, 2, 3, 6]) # 출력: 에러없음 6
calc([1, 2]) # 출력: 인덱스에러 None
또한, 위의 예제에서 else문 있는데, 이는 에러가 발생하지 않을 때 실행하게 되는 블럭이다. 그리고 finally 블럭은 항상 마지막에 실행되는 코드 블럭이다.
만약 복수 Exception들이 동일한 except 블럭을 갖는다면, 아래와 같이 이들 Expception들을 하나의 except 문에 묶어서 쓸 수도 있다.
def calc(values):
sum = None
try:
sum = values[0] + values[1] + values[2]
except (IndexError, ValueError):
print('오류발생')
print(sum)
2. 에러무시와 에러생성
발생된 Exception을 그냥 무시하기 위해서는 보통 pass 문을 사용하며, 또한 개발자가 에러를 던지기 위해서는 raise문을 사용한다.
raise 뒤에 아무것도 없는 경우는 현재 Exception을 그대로 던지게 된다. 또한 raise 뒤에 특정한 에러타입과 에러메시지 (Optional)를 넣어 개발자가 정의한 에러를 발생시킬 수 있다. 예를 들어 아래 예제는 raise 뒤에 Exception 에러타입과 에러메시지를 넣어 특별한 에러메시지를 전달하고 있다.
# pass 를 사용한 예
try:
check()
except FileExistsError:
pass
# raise 를 사용한 예
if total
<
0:
raise Exception('Total Error')
3. 파일 에러 처리 예제
아래 예제는 전형적인 파일 에러 처리를 보여주는 코드이다. 파일을 오픈할 때 에러가 발생하면, except IOError 블록을 실행한다. 파일오픈을 성공하면, try 블럭을 실행하고, finally 블럭에서 파일을 닫게 된다.
try:
fp = open("test.txt", "r")
try:
lines = fp.readlines()
print(lines)
finally:
fp.close()
except IOError:
print('파일에러')
참고로 다음은 with 문을 써서 해당 블럭이 끝나면 자동으로 파일을 닫는 코드의 예이다. Python의 with 문은 C#의 using 문과 비슷한 것으로 with 블럭이 끝날 때 자동으로 리소스를 해제하는 역활을 하는데, 특히 주목할 점은 with 블럭 내에서 어떤 Exception이 발생하더라도 반드시 리소스를 해제한다는 점이다.
with open('test.txt', 'r') as fp:
lines = fp.readlines()
print(lines)
Comprehension
1. Python Comprehension
Python의 Comprehension은 한 Sequence가 다른 Sequence (Iterable Object)로부터 (변형되어) 구축될 수 있게한 기능이다. Python 2 에서는 List Comprehension (리스트 내포)만을 지원하며, Python 3 에서는 Dictionary Comprehension과 Set Comprehension을 추가로 지원하고 있다. 또한, 종종 Generator Comprehension이라고 일컫어 지는 Generator Expression이 있는데, 이는 다음 아티클에서 Generator와 함께 설명한다.
2. List Comprehension
List Comprehension (리스트 내포)는 입력 Sequence로부터 지정된 표현식에 따라 새로운 리스트 컬렉션을 빌드하는 것으로, 아래와 같은 문법을 갖는다.
[출력표현식 for 요소 in 입력Sequence [if 조건식]]
여기서 입력 Sequence는 입력으로 사용되는 Iteration이 가능한 데이타 Sequence 혹은 컬렉션이다. 입력 Sequence는 for 루프를 돌며 각각의 요소를 하나씩 가져오게 되고, if 조건식이 있으면 해당 요소가 조건에 맞는지 체크하게 된다. 만약 조건에 맞으면 출력 표현식(Output Expression)에 각 요소를 대입하여 출력 결과를 얻게 된다. 이러한 과정을 모든 요소에 대해 실행하여 결과를 리스트로 리턴하게 된다. 쉽게 설명하면 for 루프를 돌면 특정 조건에 있는 입력데이타를 변형하여 리스트로 출력하는 코드를 간단한 문법으로 표현한 것이다.
아래 예제에서 입력 Sequence (oldlist)는 숫자, 문자 그리고 Boolean 요소를 모두 갖는 리스트이다. List Comprehension 문장을 보면 이 입력 Sequence "oldlist"로부터 요소 i 를 하나씩 가져와 이 i의 타입이 정수형인지 체크하고, 만약 그렇다면 표현식 "i * i" 를 실행하여 i의 제곱을 계산한다. 이렇게 모든 요소에 대해 계산하면 [1, 4, 9] 라는 결과 리스트(newlist)를 얻게 된다.
oldlist = [1, 2, 'A', False, 3]
newlist = [i*i for i in oldlist if type(i)==int]
print(newlist)
# 출력: [1, 4, 9]
3. Set Comprehension
Set Comprehension은 입력 Sequence로부터 지정된 표현식에 따라 새로운 Set 컬렉션을 빌드하는 것으로, 아래와 같은 문법을 갖는다. List Comprehension과 거의 비슷하지만, 결과가 Set {...}으로 리턴된다는 점이 다르다.
{출력표현식 for 요소 in 입력Sequence [if 조건식]}
아래 예제에서 입력 Sequence (oldlist)는 중복된 숫자를 갖는 리스트이다. 결과 Set은 중복을 허용하지 않으므로 중복된 데이타는 자연스럽게 제거된다. 또한 Set은 요소의 순서를 보장하지 않으므로, 아래 결과에서 보듯이 순서가 랜덤하게 바뀐 결과를 출력하게 된다.
oldlist = [1, 1, 2, 3, 3, 4]
newlist = {i*i for i in oldlist}
print(newlist)
# 출력 : {16, 1, 9, 4}
4. Dictionary Comprehension
Dictionary Comprehension은 입력 Sequence로부터 지정된 표현식에 따라 새로운 Dictionary 컬렉션을 빌드하는 것으로, 아래와 같은 문법을 갖는다. Set Comprehension과 거의 비슷하지만, 출력표현식이 Key:Value Pair로 표현된다는 점이 다르며, 결과로 dict 가 리턴된다.
{Key:Value for 요소 in 입력Sequence [if 조건식]}
아래 예제는 Id로 이름을 찾는 Dictionary (id_name) 를 반대로 Lookup 하기 위해 Key와 Value 서로 바꾼 새로운 Dictionary (name_id) 를 만든 예이다. 새 Dictionary "name_id"는 이름으로 Id를 찾는 Dictionary이다.
id_name = {1: '박진수', 2: '강만진', 3: '홍수정'}
name_id = {val:key for key,val in id_name.items()}
print(name_id)
# 출력 : {'박진수': 1, '강만진': 2, '홍수정': 3}
또 다른 예제로 아래는 if 조건식 안에 필터링 함수를 사용한 경우이다. 복잡한 조건식일 경우에는 이처럼 필터링 함수를 사용하면 편리하다. 아래 예제는 1부터 100까지 홀수를 Dictionary Key로 하고, 그 홀수의 제급을 Value로 하는 dict 객체를 생성한다.
def isodd(val):
return val % 2 == 1
mydict = {x:x*x for x in range(101) if isodd(x)}
print(mydict)
Iterator와 Generator
1. Iterator
리스트, Set, Dictionary와 같은 컬렉션이나 문자열과 같은 문자 Sequence 등은 for 문을 써서 하나씩 데이타를 처리할 수 있는데, 이렇게 하나 하나 처리할 수 있는 컬렉션이나 Sequence 들을 Iterable 객체(Iterable Object)라 부른다.
# 리스트 Iterable
for n in [1,2,3,4,5]:
print(n)
# 문자열 Iterable
for c in "Hello World":
print(c)
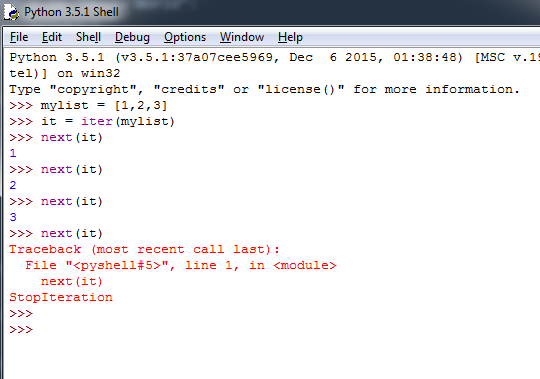
내장 함수 iter()는 "iter(Iterable객체)" 와 같이 사용하여 그 Iterable 객체의 iterator를 리턴한다. Iterable 객체에서 실제 Iteration을 실행하는 것은 iterator로서, iterator는 next 메서드를 사용하여 다음 요소(element)를 가져온다. 만약 더이상 next 요소가 없으면 StopIteration Exception을 발생시킨다.
Iterator의 next 메서드로서 Python 2에서는 "iterator객체.next()" 를 사용하고, Python 3에서는 "iterator객체.__next__()" 메서드를 사용한다. 또한, 버전에 관계없이 사용할 수 있는 방식으로 내장 함수 "next(iterator객체)" 를 사용할 수 있다. 아래는 한 리스트에 대해 list iterator를 구한 후, next() 함수를 계속 호출해 본 예이다.
어떤 클래스를 Iterable 하게 하려면, 그 클래스의 iterator를 리턴하는 __iter__() 메서드를 작성해야 한다. 이 __iter__() 메서드가 리턴하는 iterator는 동일한 클래스 객체가 될 수도 있고, 별도로 작성된 iterator 클래스의 객체가 될 수도 있다. 어떠한 경우든 Iterator가 되는 클래스는 __next()__ 메서드 (Python 2 인 경우 next() 메서드) 를 구현해야 한다. 실제 for 루프에 Iterable Object를 사용하면, 해당 Iterable의 __iter__() 메서드를 호출하여 iterator를 가져온 후 그 iterator의 next() 메서드를 호출하여 루프를 돌게 된다.
아래 예제는 간단한 Iterator를 예시한 것으로 __iter__() 메서드에서 self 를 리턴함으로써 Iterable과 동일한 클래스에 Iterator를 구현했음을 표시하였고, 그 클래스 안에 Iterator로서 필요한 __next__() 메서드 (Python 3)를 구현하였다.
class MyCollection:
def __init__(self):
self.size = 10
self.data = list(range(self.size))
def __iter__(self):
self.index = 0
return self
def __next__(self):
if self.index >= self.size:
raise StopIteration
n = self.data[self.index]
self.index += 1
return n
coll = MyCollection()
for x in coll:
print(x)
2. Generator
Generator는 Iterator의 특수한 한 형태이다.
Generator 함수(Generator function)는 함수 안에 yield 를 사용하여 데이타를 하나씩 리턴하는 함수이다. Generator 함수가 처음 호출되면, 그 함수 실행 중 처음으로 만나는 yield 에서 값을 리턴한다. Generator 함수가 다시 호출되면, 직전에 실행되었던 yield 문 다음부터 다음 yield 문을 만날 때까지 문장들을 실행하게 된다. 이러한 Generator 함수를 변수에 할당하면 그 변수는 generator 클래스 객체가 된다.
아래 예제는 간단한 Generator 함수와 그 호출 사례를 보인 것이다. 여기서 gen() 함수는 Generator 함수로서 3개의 yield 문을 가지고 있다. 따라서 한번 호출시마다 각 yield 문에서 실행을 중지하고 값을 리턴하게 된다.
# Generator 함수
def gen():
yield 1
yield 2
yield 3
# Generator 객체
g = gen()
print(type(g)) #
<class 'generator'>
# next() 함수 사용
n = next(g); print(n) # 1
n = next(g); print(n) # 2
n = next(g); print(n) # 3
# for 루프 사용 가능
for x in gen():
print(x)
위의 예에서 g = gen() 문은 Generator 함수를 변수 g 에 할당한 것인데, 이때 g는 generator 라는 클래스의 객체로서 next() 내장함수를 사용하여 Generator의 다음 값을 계속 가져올 수 있다. Generator는 물론 예제의 마지막 부분과 같이 for 루프에서 사용될 수 있다.
리스트나 Set과 같은 컬렉션에 대한 iterator는 해당 컬렉션이 이미 모든 값을 가지고 있는 경우이나, Generator는 모든 데이타를 갖지 않은 상태에서 yield에 의해 하나씩만 데이타를 만들어 가져온다는 차이점이 있다. 이러한 Generator는 데이타가 무제한이어서 모든 데이타를 리턴할 수 없는 경우나, 데이타가 대량이어서 일부씩 처리하는 것이 필요한 경우, 혹은 모든 데이타를 미리 계산하면 속도가 느려서 그때 그때 On Demand로 처리하는 것이 좋은 경우 등에 종종 사용된다.
3. Generator Expression
Generator Expression은 Generator Comprehension으로도 불리우는데, List Comprehension과 외관상 유사하다. List Comprehension은 앞뒤를 [...] 처럼 대괄호로 표현한다면, Generator Expression (...) 처럼 둥근 괄호를 사용한다. 하지만 Generator Expression은 List Comprehension과 달리 실제 리스트 컬렉션 데이타 전체를 리턴하지 않고, 그 표현식만을 갖는 Generator 객체만 리턴한다. 즉 실제 실행은 하지 않고, 표현식만 가지며 위의 yield 방식으로 Lazy Operation을 수행하는 것이다.
아래 예제는 1부터 1000개까지의 숫자에 대한 제곱값을 Generator Expression으로 표현한 것으로 여기서 Generator Expression을 할당받은 변수 g는 Generator 타입 객체이다. 첫번째 for 루프를 사용하여 10개의 next() 문을 실행하여 처음 10개에 대한 제곱값만을 실행하였다. 두번째 for 루프에서는 11번째부터 마지막까지 모두 실행하게 된다. Generator 객체 g는 상태를 유지하고 있으므로 두번째 for 루프에서 다음 숫자 11부터 계산을 수행한 것이다.
# Generator Expression
g = (n*n for n in range(1001))
# g는 generator 객체
print(type(g)) #
<class 'generator'>
# 리스트로 일괄 변환시
# mylist = list(g)
# 10개 출력
for i in range(10):
value = next(g)
print(value)
# 나머지 모두 출력
for x in g:
print(x)